Structured JSON Output from Small LLMs
1,500+ tests across 7 models. Forcing JSON Mode degraded 2 of 3 models. A 2B model beat a 7B on defaults.
Scope & limitations — read first
1,500+ tests · 7 models (2B to 9B) · open-source only · run locally on Apple Silicon
You know that feeling when you ask an AI to return data in a specific structure, and everything looks clean — but the actual content is quietly wrong?
I ran 1,500+ tests across 7 small open-source models (2B to 9B parameters). These are the models teams actually self-host to save costs and keep data private. Here's what I found:
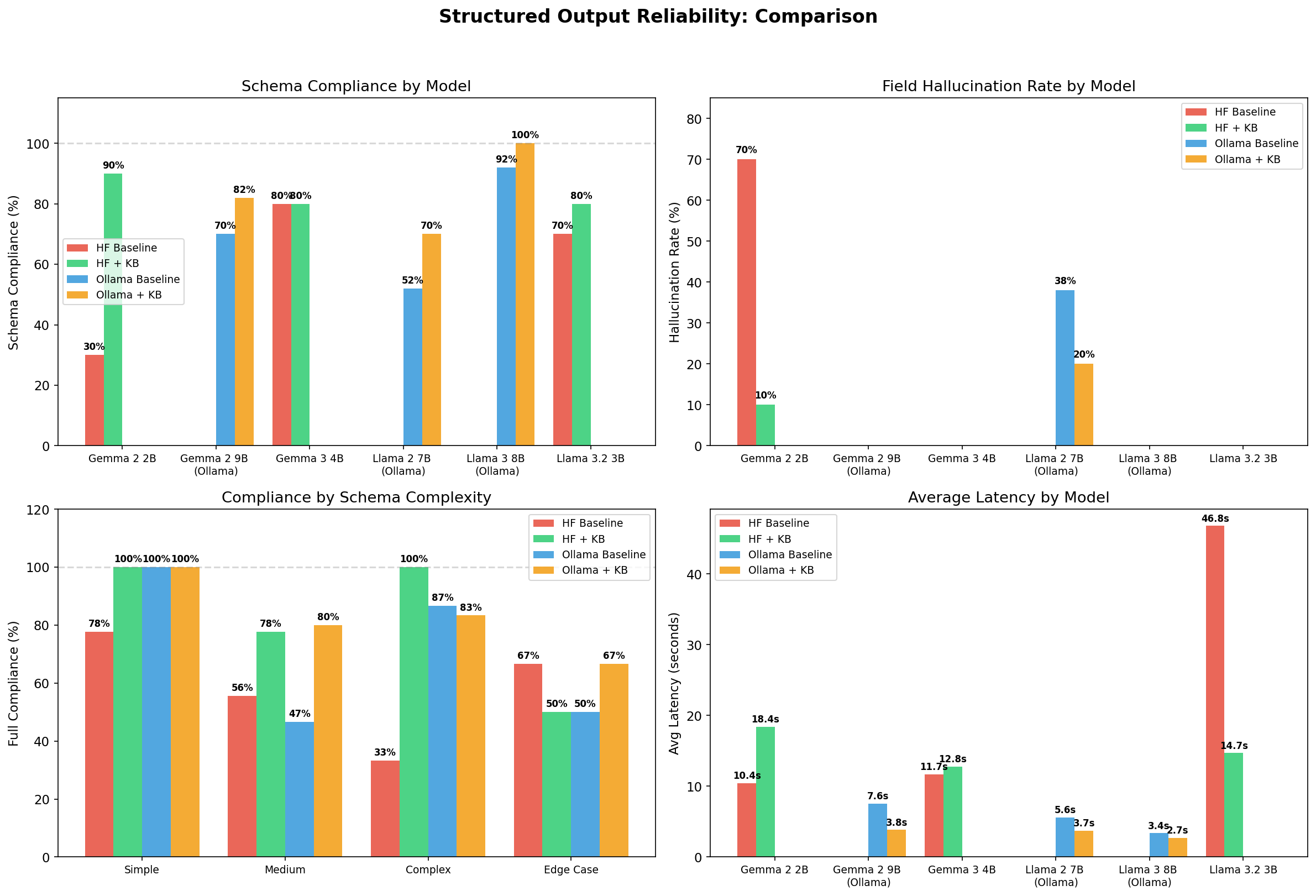
1. Forcing a strict format can backfire
Most assume that forcing a strict format (like "JSON Mode") improves accuracy. It often does the opposite. Two out of three models got worse when I forced strict formatting. One 9B model dropped from perfect accuracy to 92%. The output looked prettier, but the reasoning was less reliable.
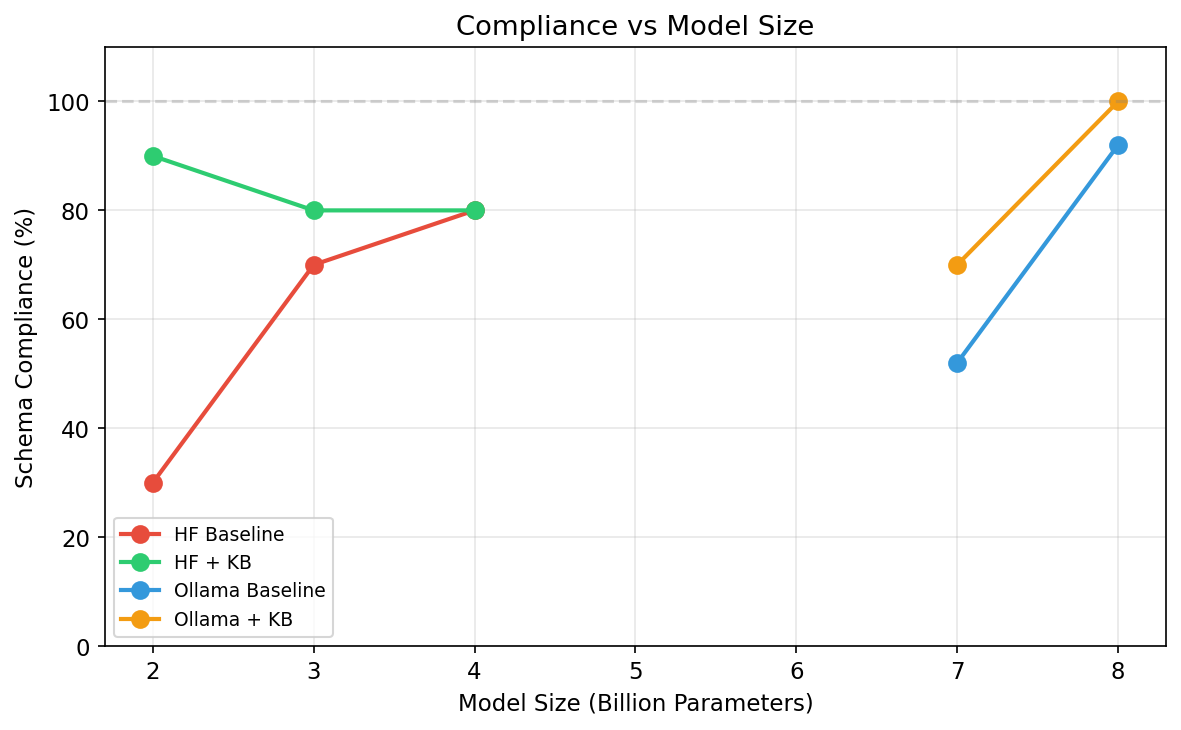
2. A 2B model beat a model 4x its size
At this scale, architecture and instructions matter more than raw parameter count. As models get larger, this gap narrows — but even 20B+ models still benefit from structured guidance on complex tasks.
3. Every small model family fails differently
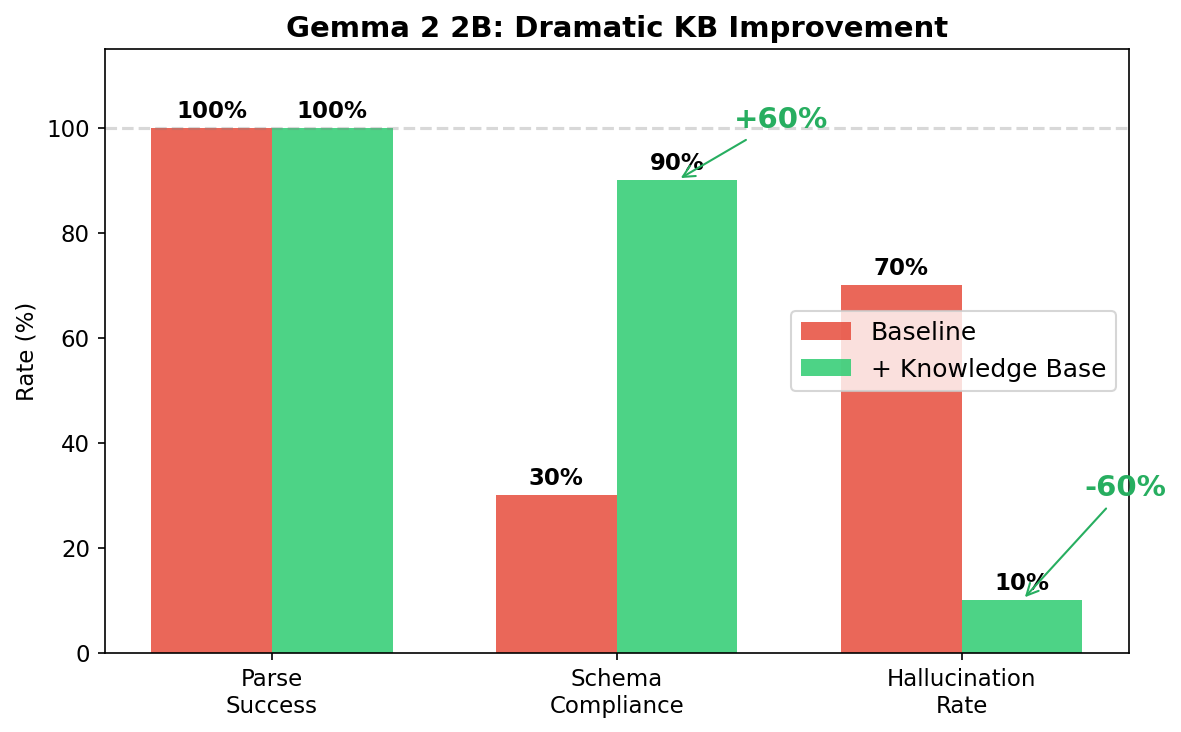
One family kept getting data types wrong, while another invented entirely new fields. The baseline 2B model hallucinated fields 70% of the time, while the 7B model hit 38%. If you run small models for cost or privacy, you must know which specific mistakes your model family tends to make.
4. The "Complexity Cliff"
On basic requests, small models scored 100%. But on edge cases — the kind you actually encounter in production — accuracy dropped to 67%. This is where small models need the most help.
5. Only 1 rule actually held it all together
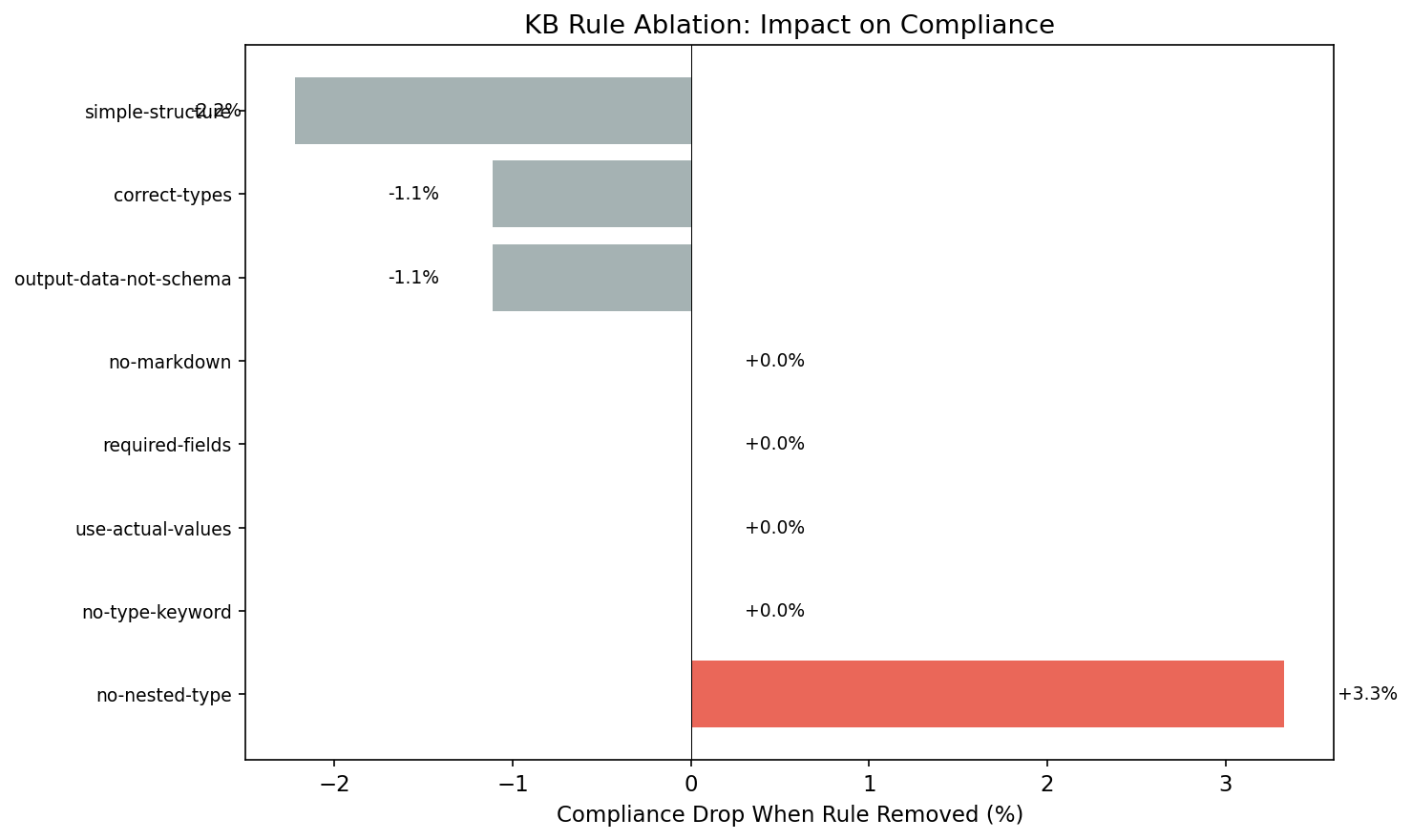
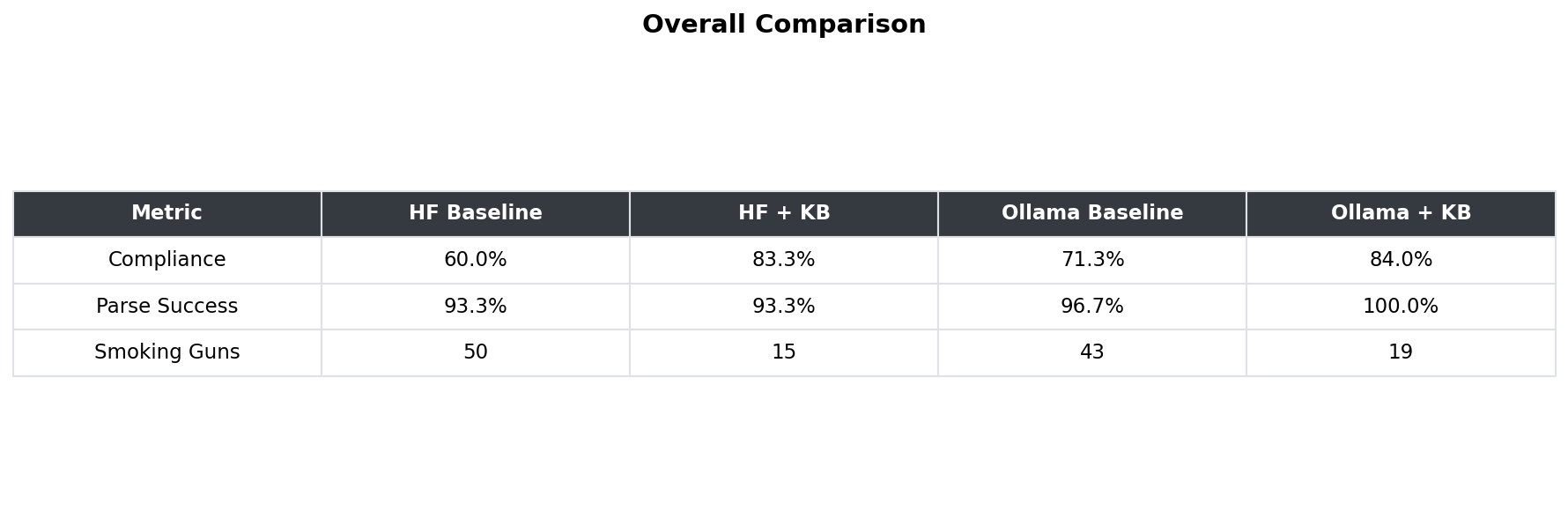
I tested 8 guidance rules by removing them one by one. Seven made no difference. One specific rule — telling the model not to confuse data structure definitions with actual data — was the only thing holding accuracy together. Without it, compliance dropped immediately.
Open questions
Does this pattern hold for larger models (20B+)?
What other single instructions have outsized impact on compliance?
How do these results compare to commercial API models?
Comments