Context Position Bias in Small LLMs
Stanford showed GPT-3.5 loses middle-context info. Do small open-source models behave the same way?
Scope & limitations — read first
3 models · 7 positions tested · ~500 trials per model · run locally on Apple Silicon · replication of Liu et al., 2023
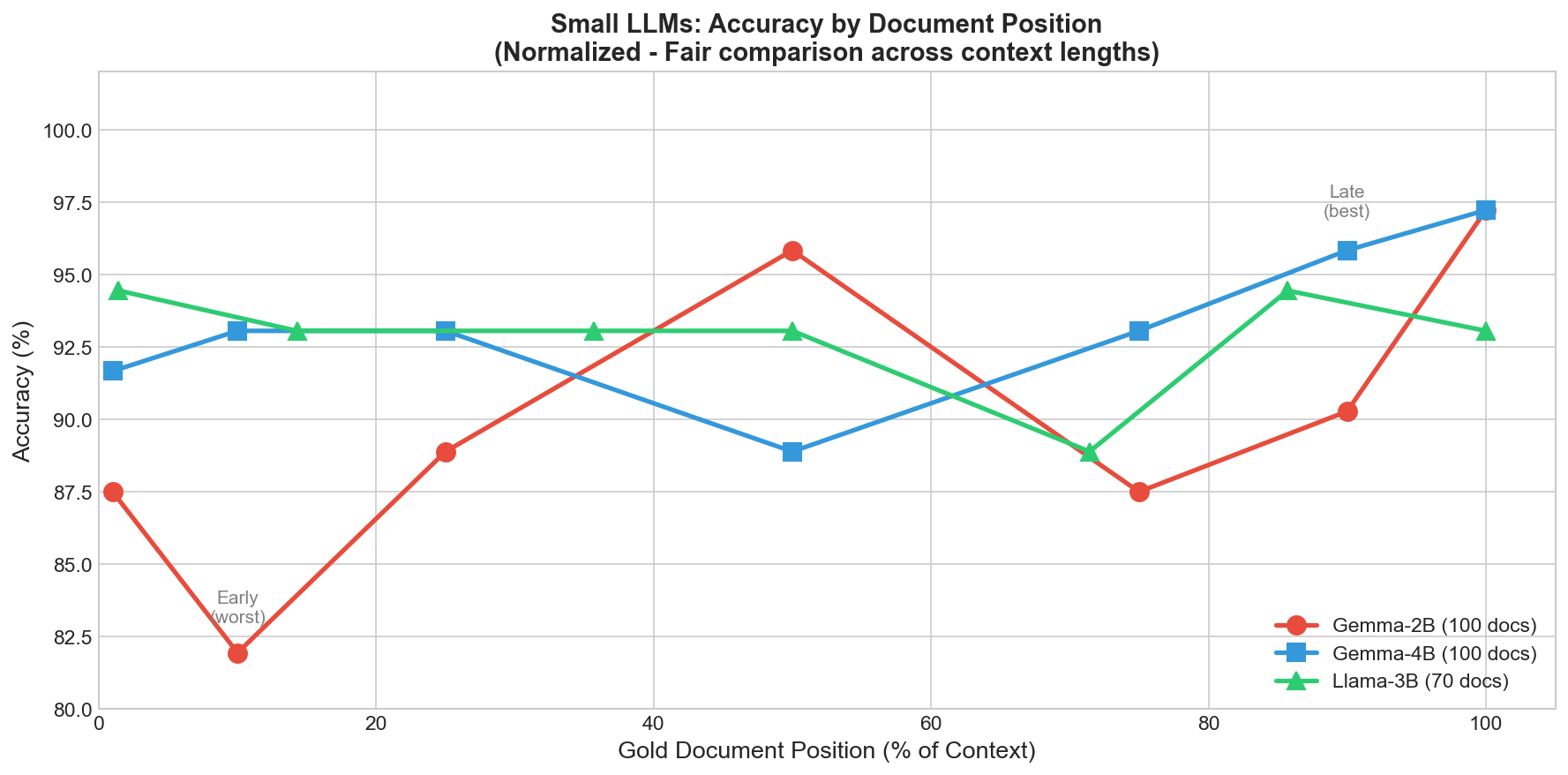
The "Lost in the Middle" paper (Liu et al., 2023) showed that large models like GPT-3.5 perform worst when important information is buried in the middle of long contexts — a U-shaped accuracy curve.
Do small open-source models (2–4B parameters) behave the same way?
The Setup
- Models: Gemma-2B, Gemma-4B, Llama-3B
- Context: 70–100 documents per prompt with 7 hard distractors per question
- Scale: 7 positions tested, ~500 trials per model
- Hardware: Run locally on Apple Silicon
Results
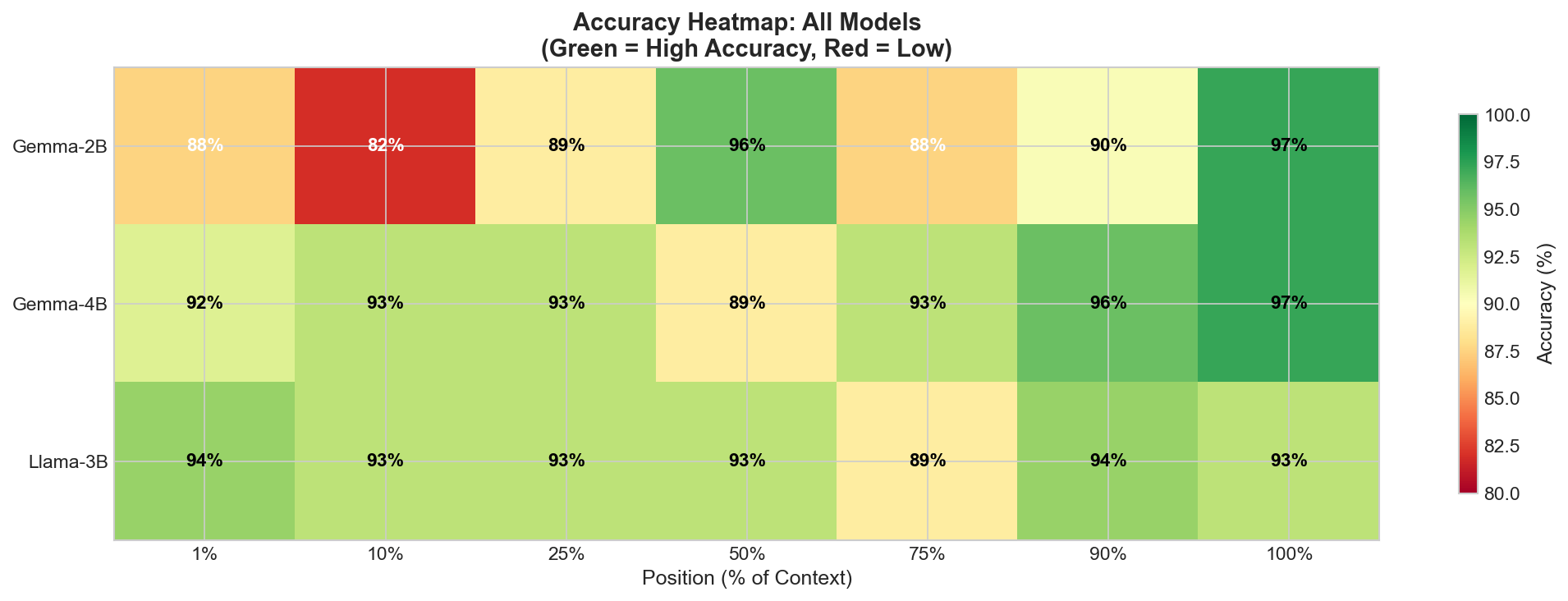
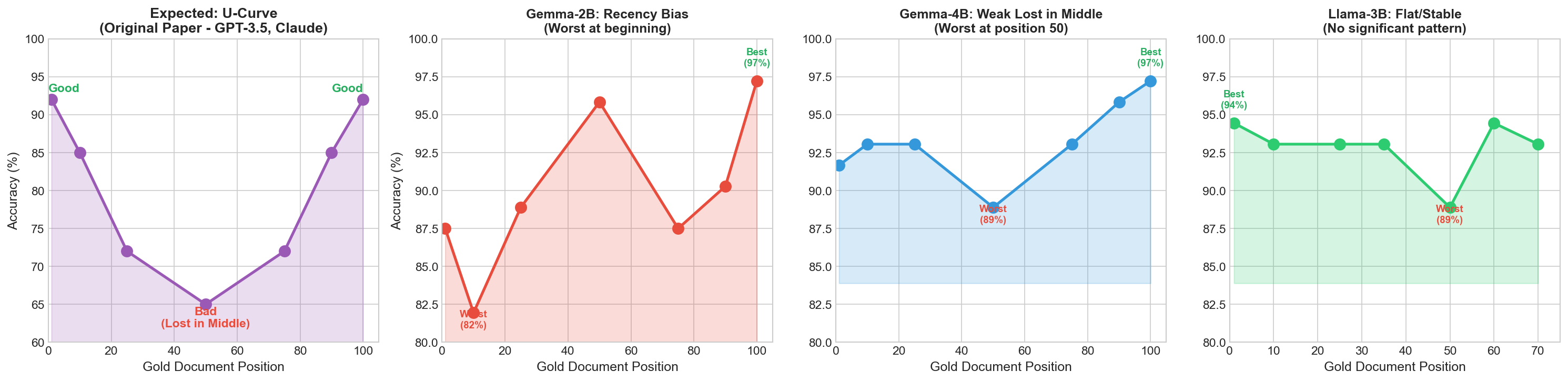
Gemma-2B (Recency Bias)
Gemma-4B (Weak Middle Dip)
Similar upward trend, but its weakest point was actually position 50 (88.9%) — hinting at a mild middle dip. Not statistically significant (p=0.198).
Llama-3B (Flat/Stable)
Completely flat. Early and late positions were identical. No significant position effect (p=1.0).
The Lesson
- Run the stats: My first pass at n=30 showed "trends" that vanished or reversed at n=72.
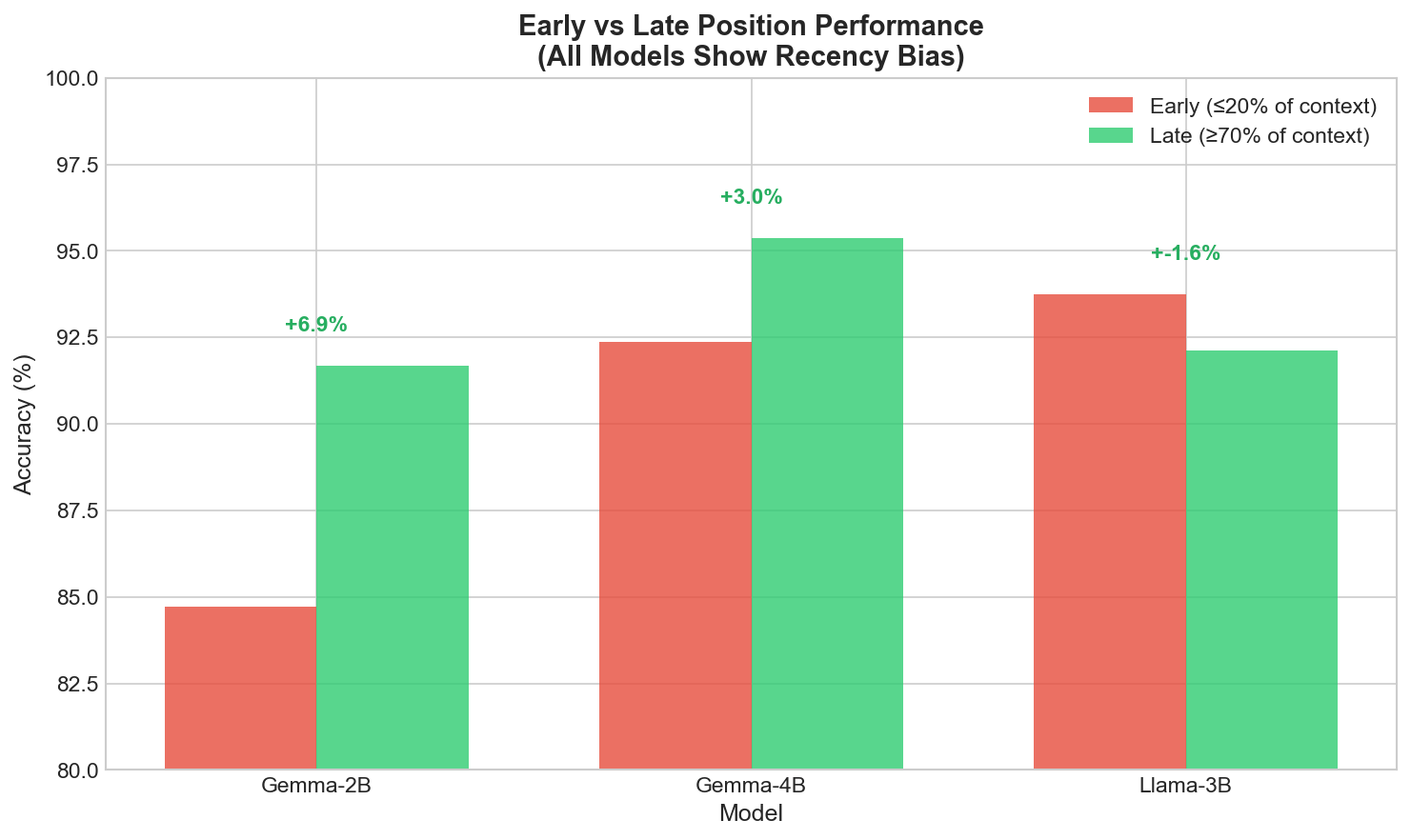
- Know your model: If you use Gemma-2B, document ordering is critical (put the best chunk last). If you use Llama-3B, it's far less sensitive.
Open questions
Does position bias change with different chunking strategies?
How does this interact with retrieval ranking in production RAG?
Do fine-tuned variants of these models show different patterns?
Comments