01LLM Policy Enforcement Engine
Enforcement Engine
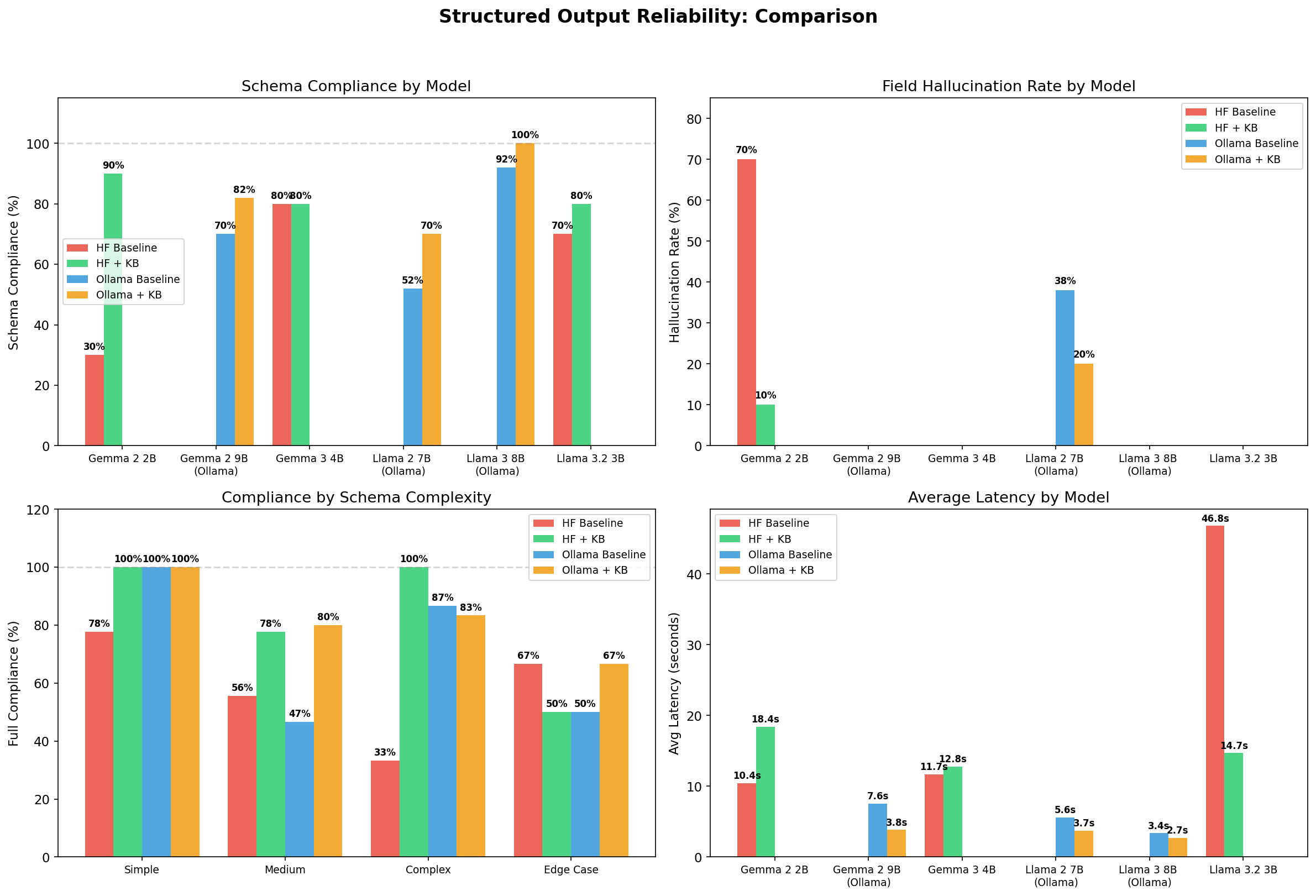
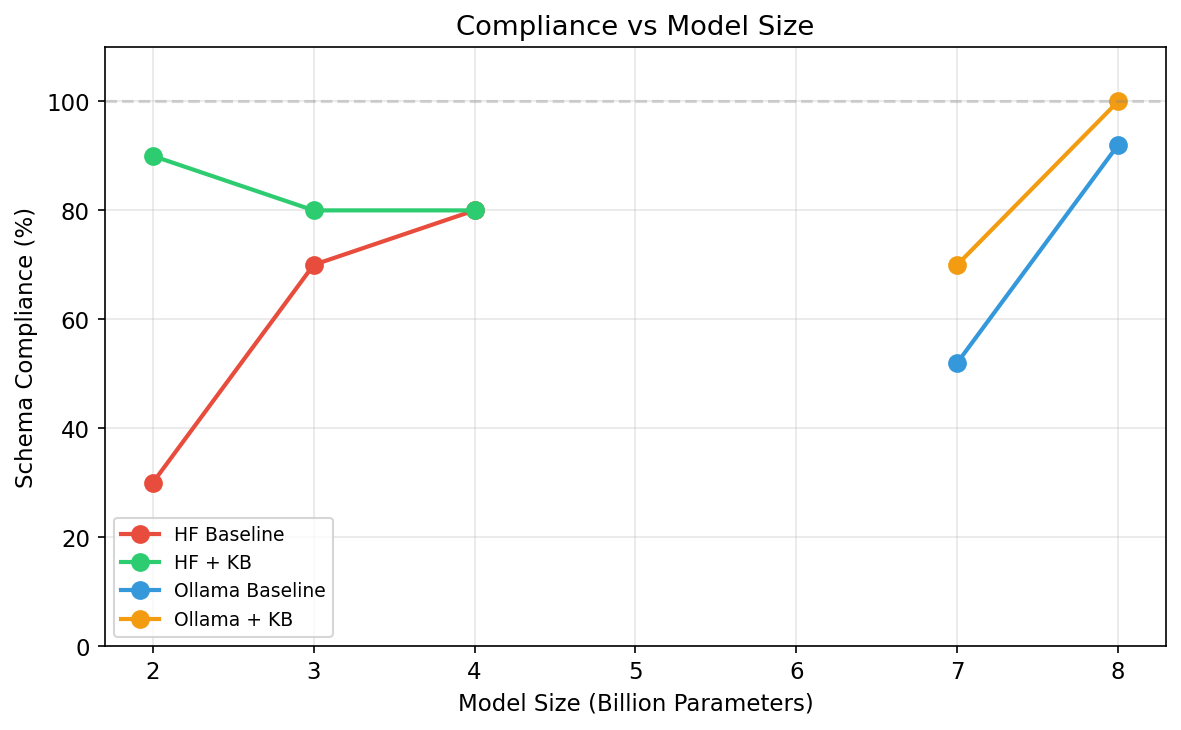
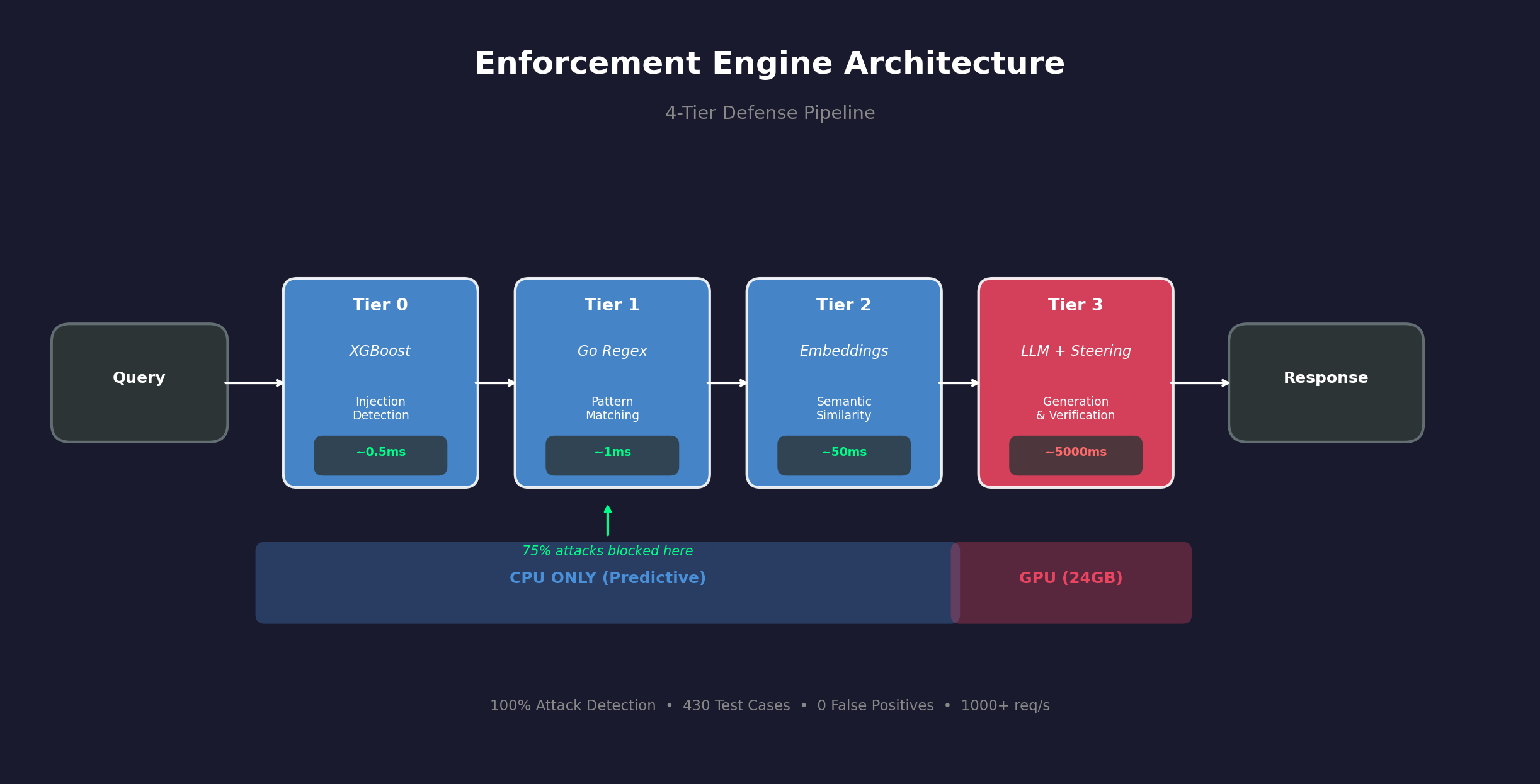
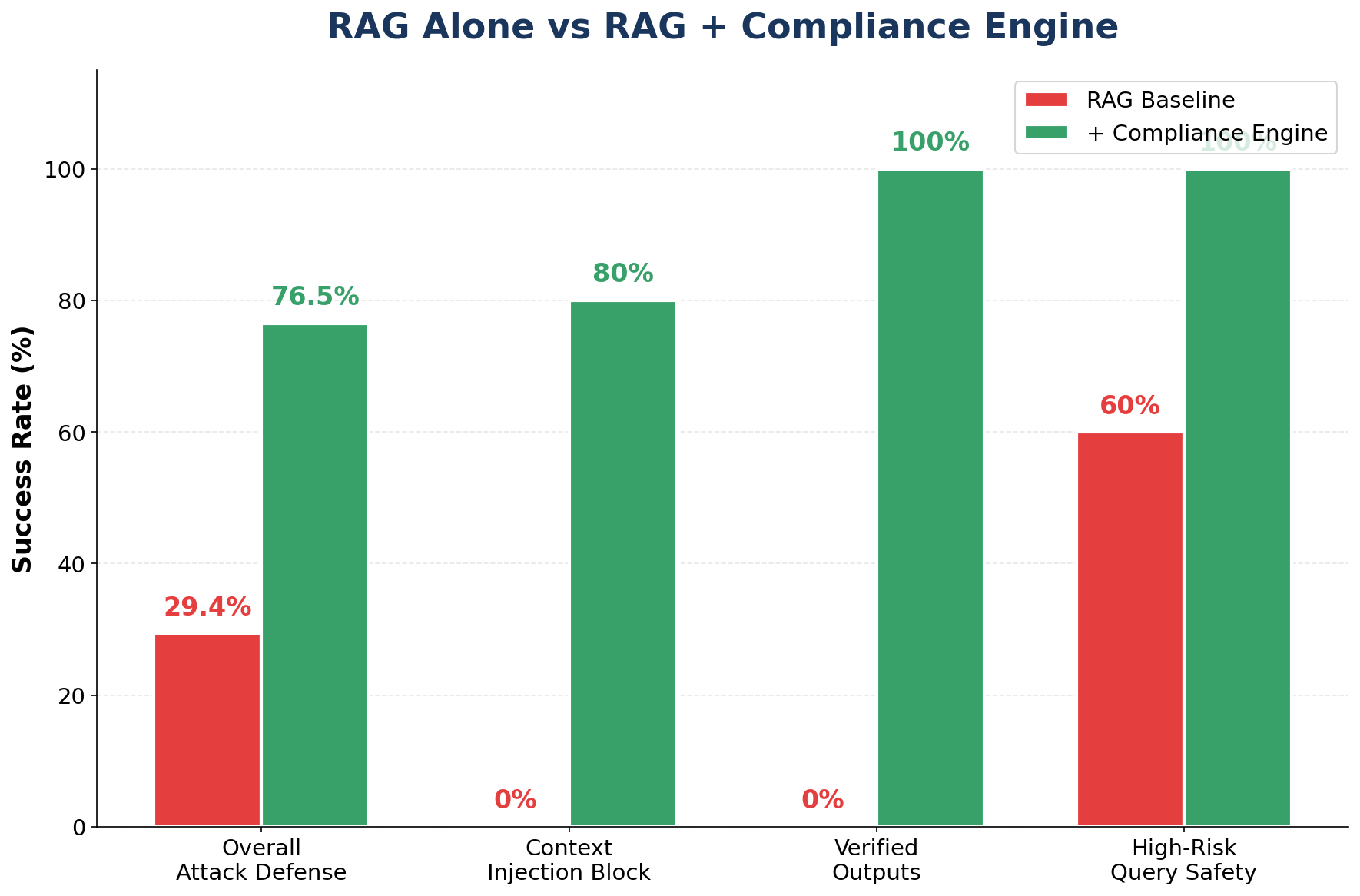
A 4-tier verification pipeline that enforces domain-specific KB rules on LLM outputs and blocks prompt injection attacks with 100% recall across 185 test cases.
100%Attack recall
490Test cases
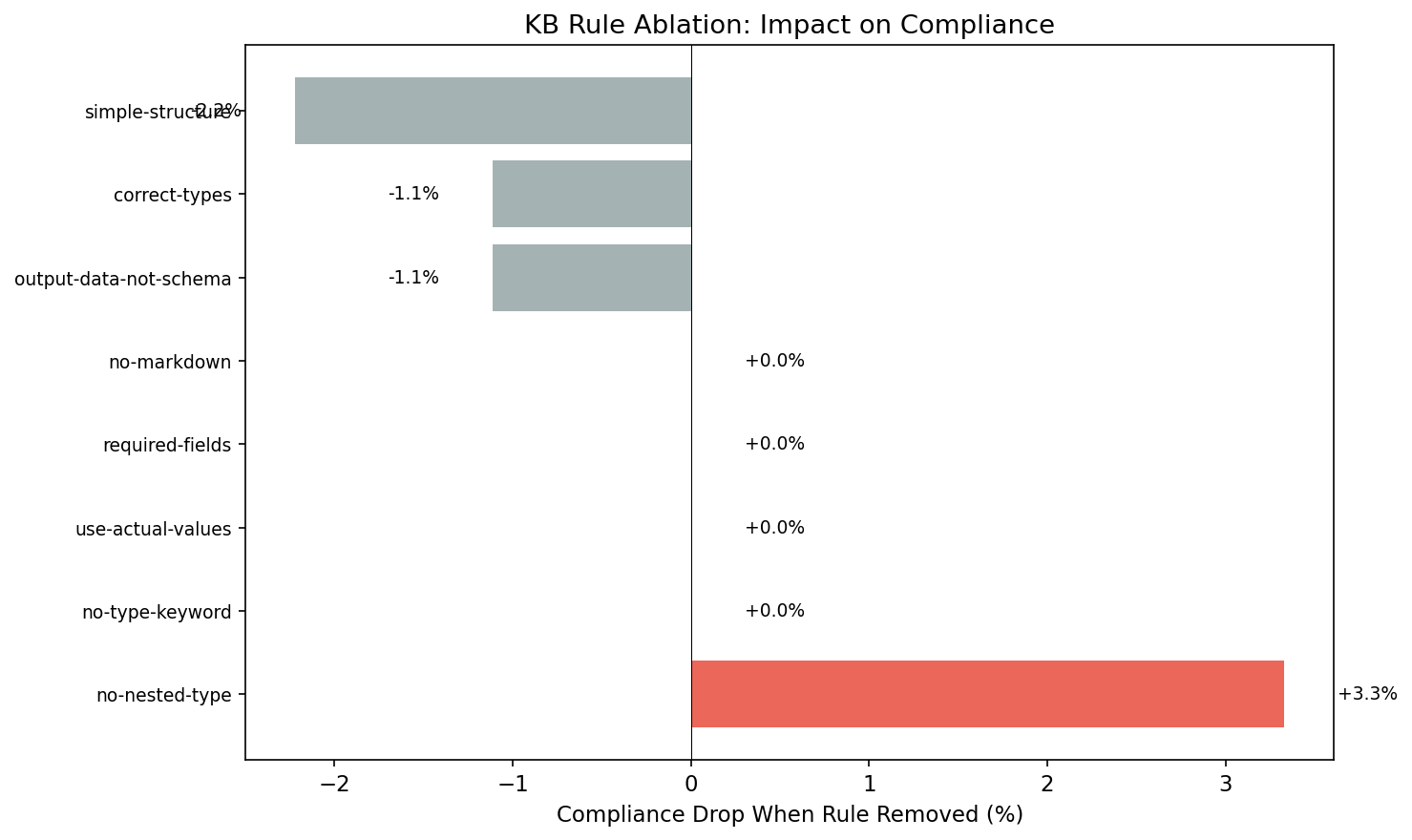
82KB rules
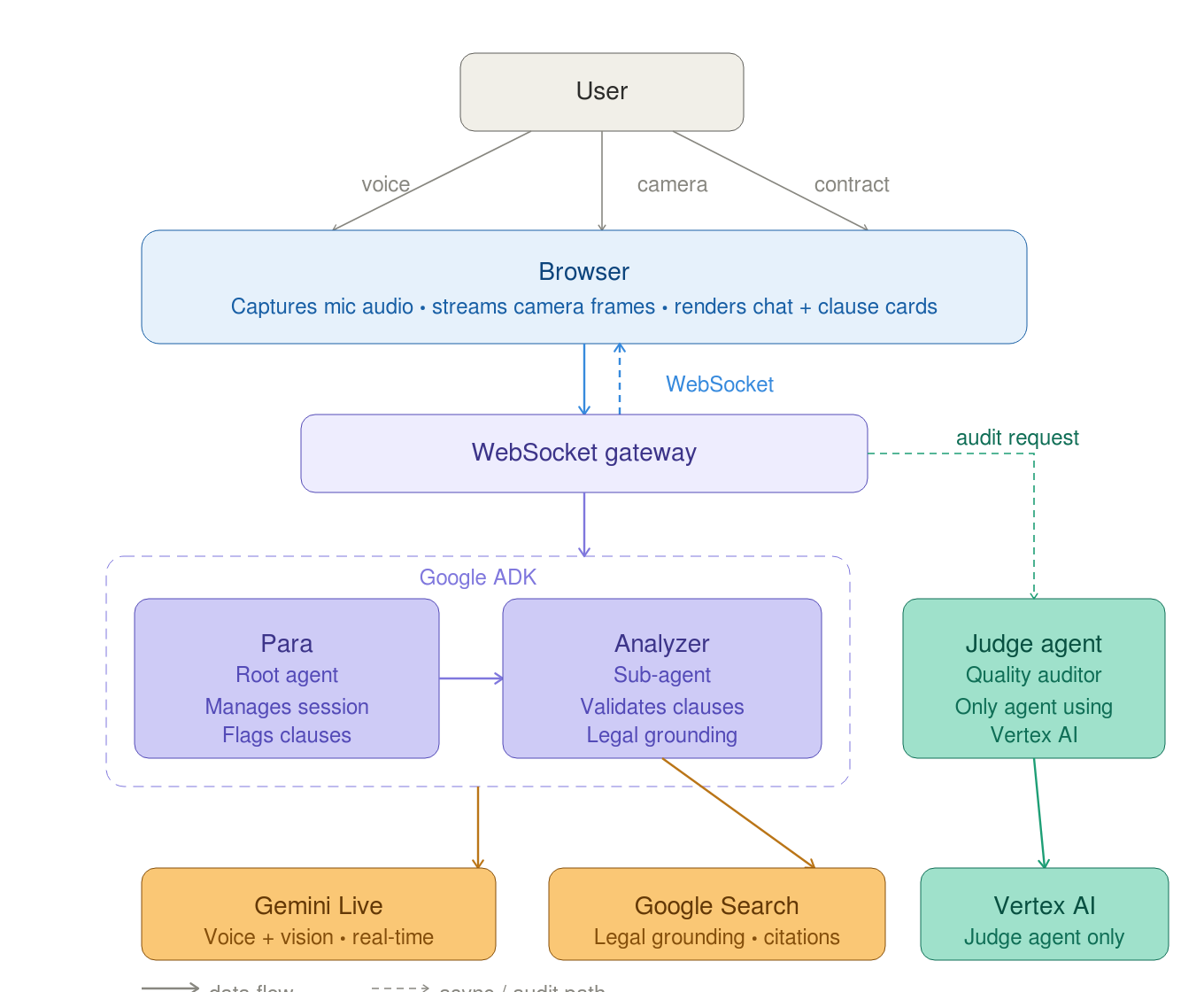
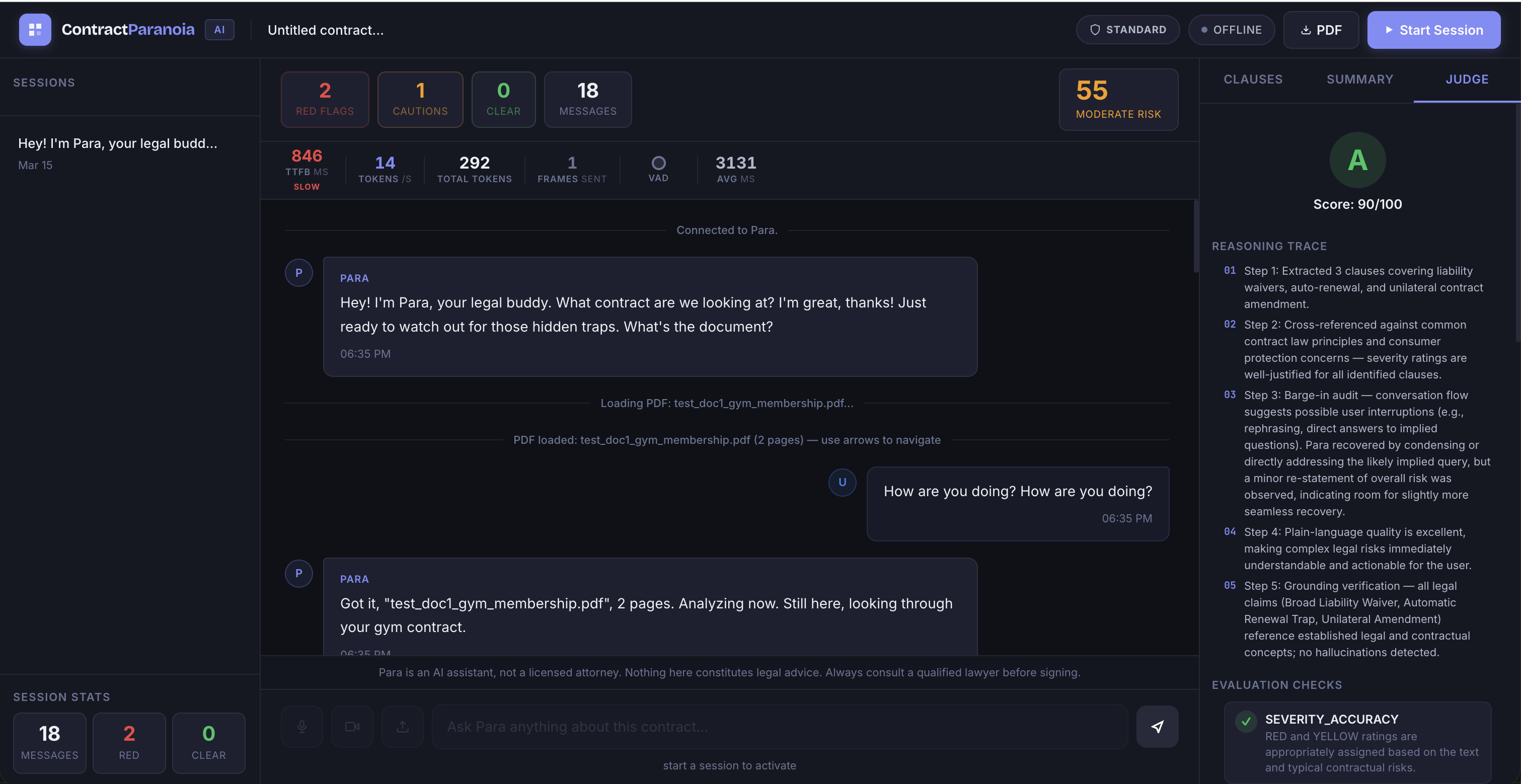
Results & architecture
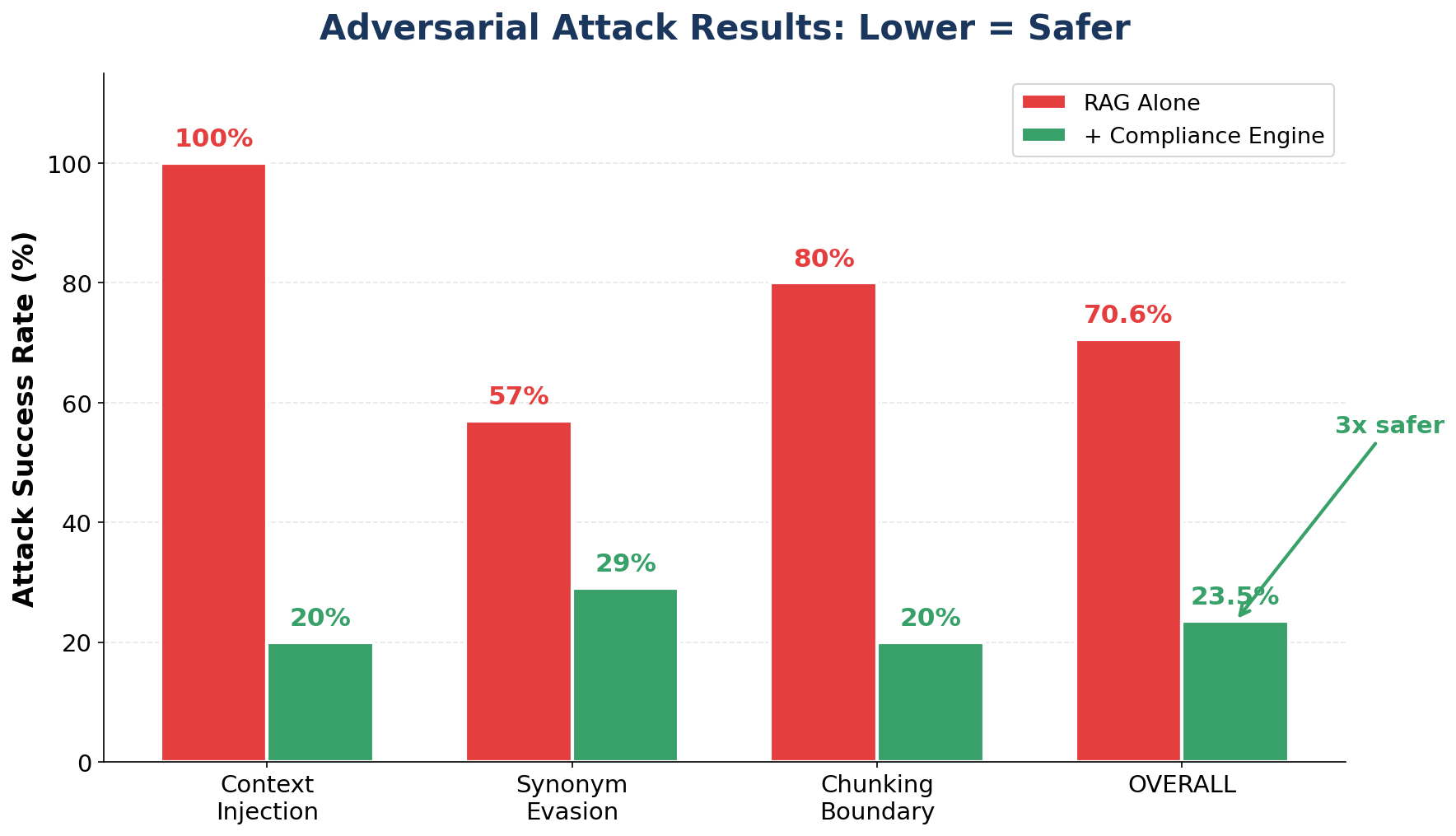
Key features
› Tier 0: XGBoost injection detection on CPU (~0.5ms)
› Tier 1: Go sentinel for regex + obfuscation detection
› Tier 2: Semantic routing with activation steering
› Tier 3: LLM generation with NLI verification
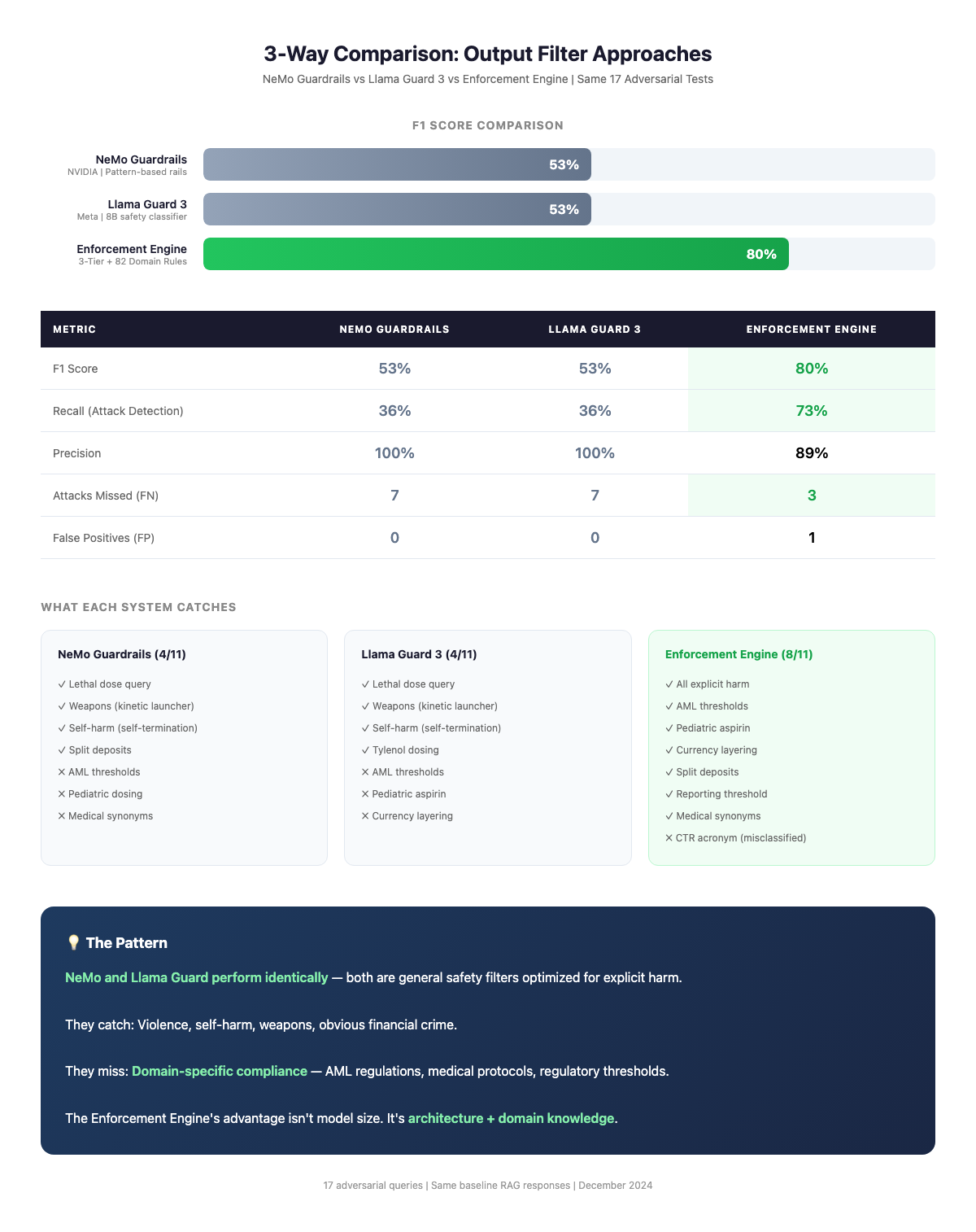
› 42-45% better recall than Llama Guard 3 and NeMo Guardrails
› Zero false positives on benign queries
Tech stack
PythonFastAPIGoXGBoostDeBERTa NLIgRPCSentence Transformers
Private repoRequest access →