Fine-Tuning Gemma 4 E2B: Notes from a Weekend
LoRA on the text decoder, ~5,000 training pairs. Three observations about probability distributions, prompts, and what fine-tuning quietly erased.
Scope & limitations — read first
Gemma 4 E2B (gemma-4-e2b-it, ~5.1B total / ~2B active text decoder) · bf16 · LoRA r=32, α=64 on q/k/v/o + gate/up/down projections · vision and audio towers frozen · ~5,000 training examples · 134 test generations across 23 query types · M-series Mac · ~30 sec per query
This weekend I fine-tuned Gemma 4 E2B for Python code gen. LoRA on the text decoder, vision/audio towers frozen. ~5000 training pairs. The fine-tune worked fine. Bad outputs across 134 tests went from ~5% to 0% greedy, 1.5% sampled.
The surprising stuff was the debugging.
First — random Python 2 syntax in outputs
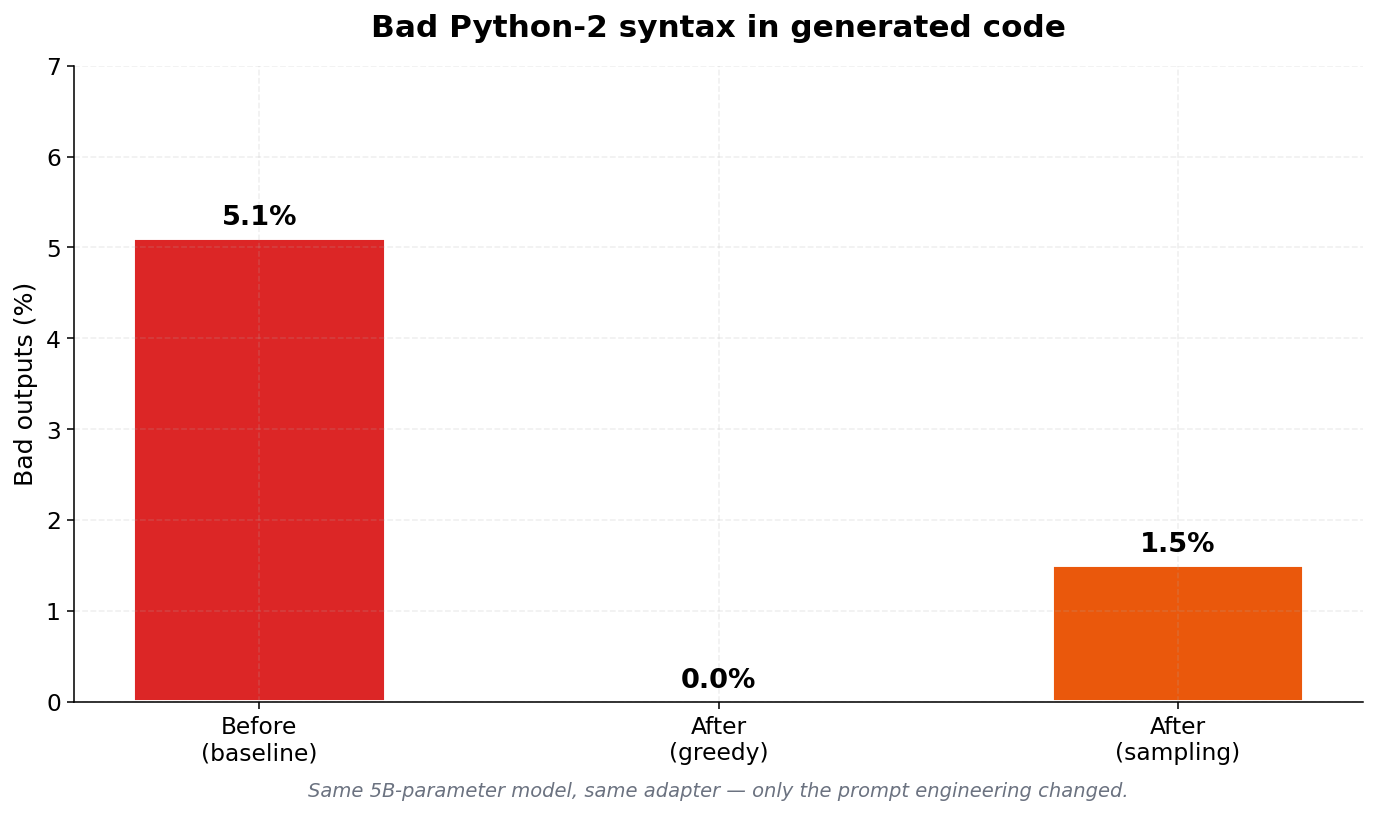
~5% of test cases. Instrumented top-K probabilities at every token. On one bad output the wrong answer sat at 55% probability, the right answer at 38%. Went back to the data, found a regex gap that let through hundreds of training pairs with old syntax. The model just... learned them. At almost exactly the rate they appeared in training.
Second — added "prefer Python 3, not Python 2" to the prompt
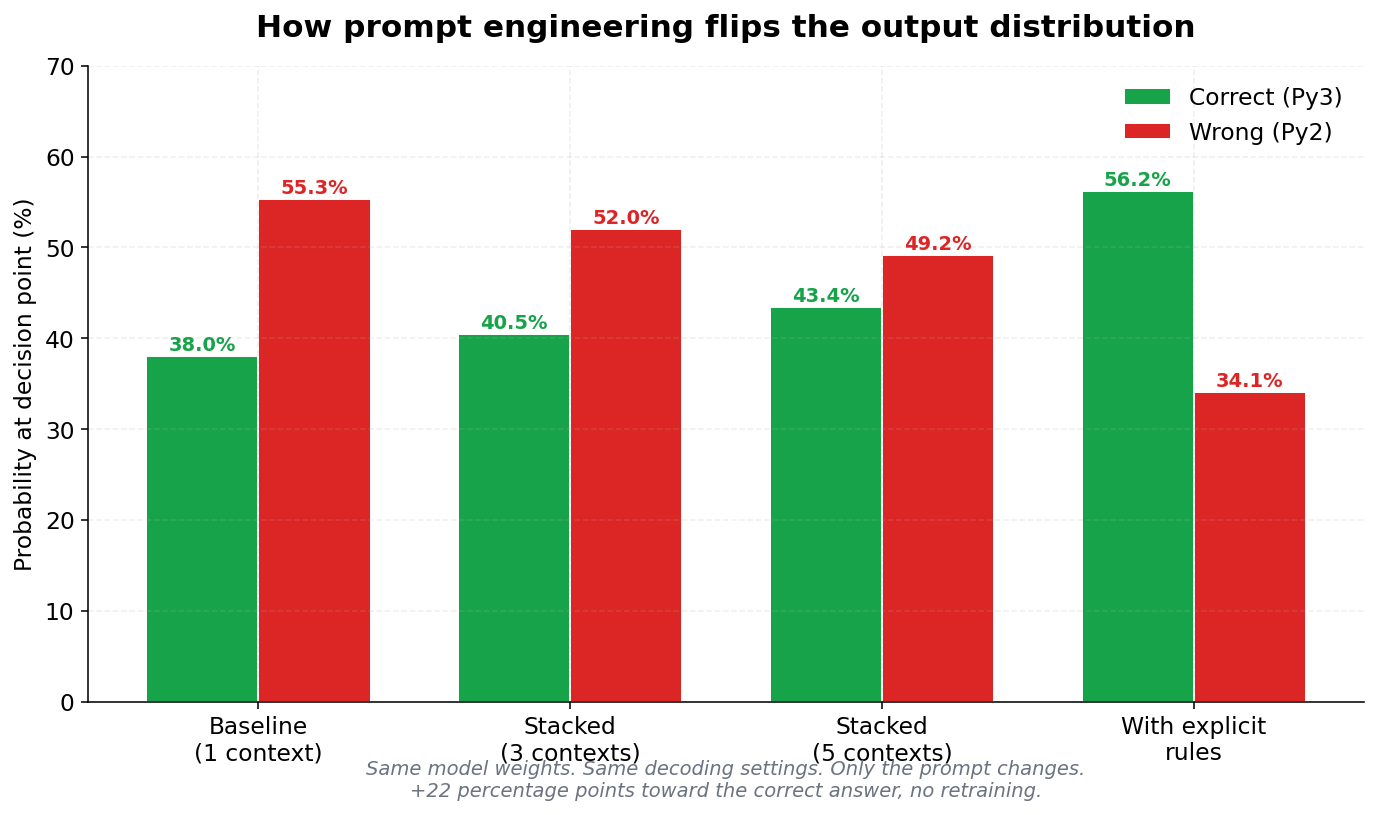
Same decision point flipped to 56/34. No retraining. Just words. Same weights, totally different output.
Third — fed the fine-tuned model a deliberately broken instruction
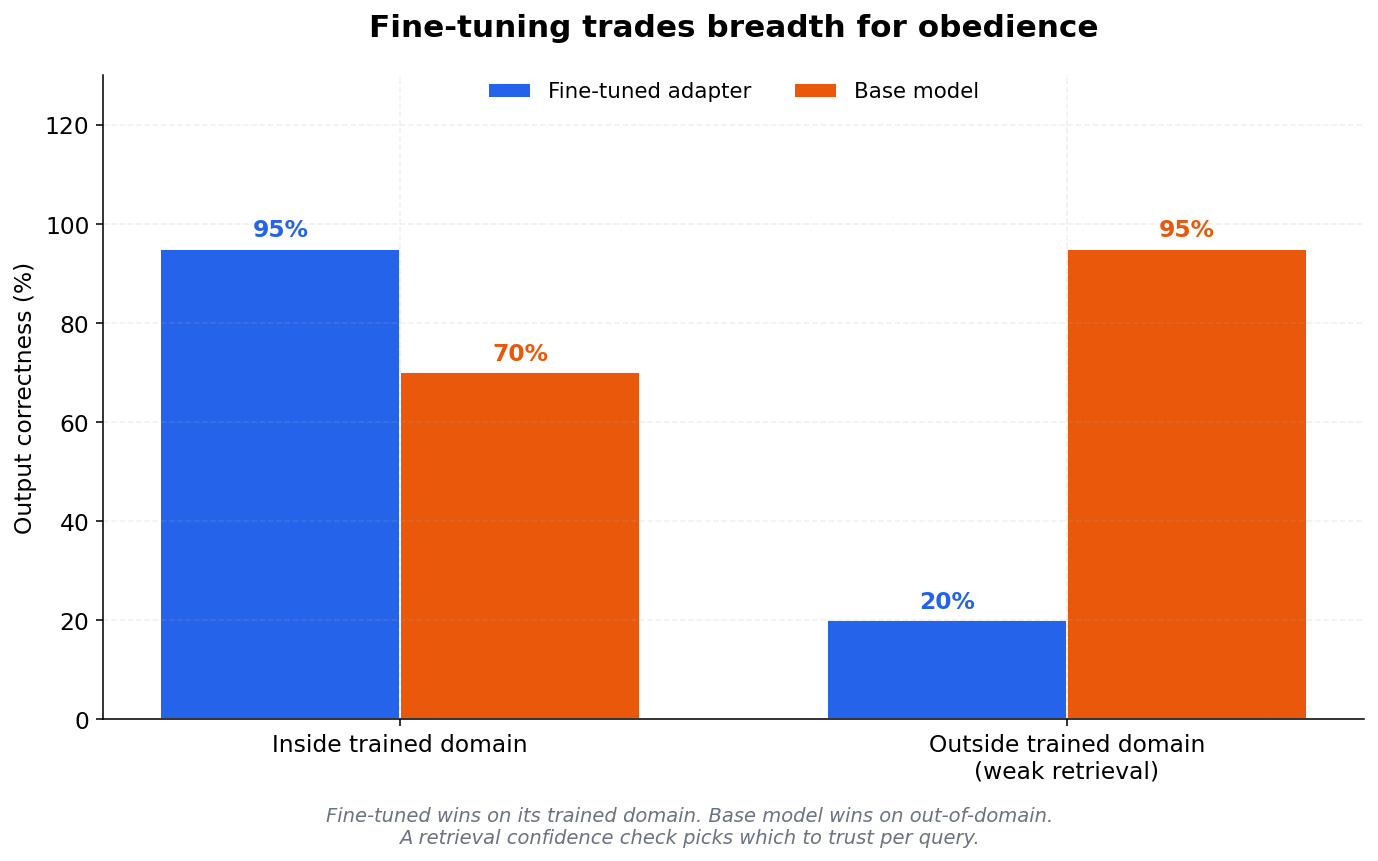
I fed the fine-tuned model a deliberately broken instruction (specs were contradictory) just to see what would happen. It wrote 60 lines of code that confidently did the wrong thing. Same prompt through base Gemma without my adapter — it pushed back.
First reaction: "fine-tuning made it sycophantic." Not quite right. Base didn't resist because it's smarter. It resisted because Google's RLHF included disagreement signals. My fine-tune didn't add a bug — it erased them.
The real failure isn't fine-tuning. It's training on positive-only examples. All 5000 of my pairs were "good instruction → correct code." Zero pushback examples. So the adapter never learned "this spec is wrong" was a valid response. Same failure shows up in base RLHF without disagreement signal — exactly what sycophancy research measures.
Ended up adding a retrieval-confidence check — fall back to base when retrieval is weak. That one thing mattered more than the fine-tune.
Karpathy's MicroGPT post got me to instrument all this.
His thesis: LLMs are statistical engines, not reasoners. Data, prompt, fine-tune — different levers, same surface.
Test coverage
Four questions I'm curious about
- Does anyone train with adversarial pairs ("wrong instruction → pushback") in their fine-tunes? Or is this skipped because constructing negative examples is a pain?
- Is the "narrow positive-only training → loses healthy pushback" pattern something you've seen elsewhere — base RLHF, instruction-tuned models, your own fine-tunes?
- Same question for RAG and few-shot — when you inject "good example" retrievals into the prompt, does the model just follow them even when the user query doesn't quite match? Same root cause, different surface. Hit this in production RAG?
- Security — is anyone doing safety regression tests after fine-tuning on narrow positive-only data? Feels like a supply-chain risk: every team fine-tuning a "safe" base model is potentially shipping a less-aligned one without knowing.
Open questions
Would the same three lessons hold at larger scale (70B+) where pretraining dominance is even stronger?
Does the retrieval-confidence gating threshold transfer across model families, or is it model-specific?
How much of the +22pt prompt-conditioning effect is recoverable through better fine-tuning data alone?
What's the right way to detect 'context the model shouldn't trust' before generation, not after?